
This post was originally published at https://selenachau.wordpress.com/2017/01/02/work-smarter-not-harder-pyth...
Being able to start this blog post with a panda gif makes me incredibly happy. However, what I'm really talking about is Pandas, the data analysis library for Python programming. I'm intrigued by the possibilities of programming for library and archives so I'm sharing my beginner's journey. Being a beginner, I can tell you that learning how to put together this script took a lot of reading and hands-on learning time. The non-spoiler is that through this journey I realize there is much, much more for me to learn about Python. I'd also love to know more ways in which libraries and archives are implementing programming solutions! Please let me know if you know of any.

There are a lot of cool things scripting and programming can do--computing to save manual work and people time--especially in archives and libraries. Libraries and archives work with the growing amount of data and the challenge to keep it accessible. There are often metadata schemas, metadata crosswalks, and data preparation work to move information from one system to another. KBOO has a database with a particular structure. AAPB has a database with a particular structure. Finding a way to transform data from one structure to another programmatically would be great!
A refresher on why we do this: http:// www.slideshare.net/vladimirbvega/metadata-mapping

Adam is my go-to guy in our cohort for Python questions. And, he is giving a public webinar on Python basics, so mark your calendars:
Thursday 2/23/2017, 3:00 PM EST
Webinar: "Intro to Data Manipulation with Python CSV" (Adam Lott)
Links to the public webinars will be posted on Twitter and the AAPB blog, and promoted through various public listservs.
Our NDSR cohort keeps in touch with archiving and digital preservation topics in our Slack channel so I would wonder if something could get done with Python, send him some files, and he would send me the answer with the ability to explain it genially and hear my follow up questions. I didn't want to take advantage of his generosity so it was time for me to do some Python learning on my own. But, along the way I learned that I was really using Pandas more than standard Python programming.
For people who want to dabble and not install python on their own computers yet, I found these two online Python environments: https://wakari.io/ and https://www.sourcelair.com/.
Notes:
- A basic understanding of the command line interface is required. The command line is different for Windows than Mac.
- Even though I installed both Python 2.7 and 3.5 on my Mac, I'm not in a place to decide to use one over the other. I learned that many developers are using Python 3.5 but existing tools written in 2.7 may not be compatible with Python 3.5. This can be read more about here. The newest version of Pandas is compatible with multiple versions of Python.
- Why not use Python's csv module for data manipulation? There's probably a parallel solution using Python CSV. However, I found answers to my questions with Pandas more easily than with Python CSV. That being said, Pandas is extremely robust and probably a more powerful tool than I need for my exploration with data manipulation.
- There are probably multiple ways within Python to get to the same end result, I haven't explored all the libraries and modules.
My goal was to take a csv and reformat it. After installing Python and Pandas, I searched Google for basic Python introductory exercises involving reading a csv to get used to writing the code. I read a bunch of stackoverflow messages and looked at examples others were working with. For me, using the logic of programming languages to get to an end result is like a puzzle. My awesome roommate is into jigsaw puzzles, so I think of this "figuring things out" learning time period as doing puzzles as well.
Some basics with writing a Python script:
- Use a *.py extension. I am using TextWrangler on my Mac and Notepad++ on the PC at work (both free)
- Import python modules at the top of your code
- I add comments to keep track of notes to myself
- Learning the terminology, logic, and formatting of Python may not be the most natural way for a human to think, but it is consistent and defined. For example, a dataframe is "a 2-dimensional labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table." Or, thinking of the data type string as similar to plain text.
- Try things! Give yourself time to have the language make sense to you. If something is not right, the language will produce an error which can guide you to fixing your script.
My goal: csv database export => data in AAPB's Excel template format
(see http://americanarchive .org/help/contribute)
What do I want to do with the data?
- Keep a smaller set of the original csv columns
- Add new columns with known data values, per AAPB request
- Reformat some column data. Separate Subject terms held in one column into multiple columns, and do the same for Contributor names.
- Match the AAPB column headers as much as possible
- Replace 'nan' with '' (I learned later that programming languages have a specific ways of managing missing data)
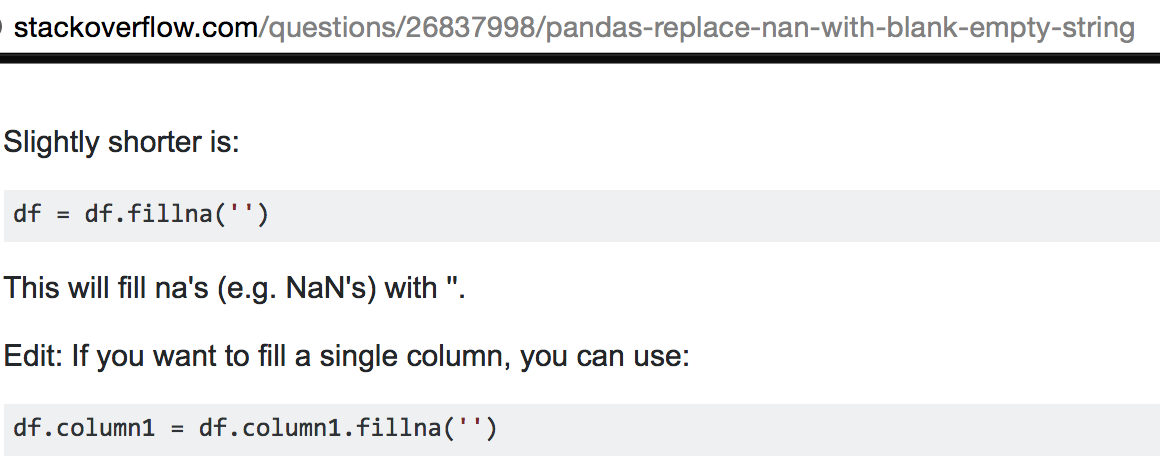
What I came up with:
https://github.com/selenachau/kboo-python-pandas-test /blob/master/EditCsvForAAPB.py
I ended up separating the work into three parts. Mostly this was because I wanted the subjects and contributors columns to be split into different columns based on a comma delimiter but I didn't want an entire row of data to be split based on a comma delimiter (think about commas used in a description field).
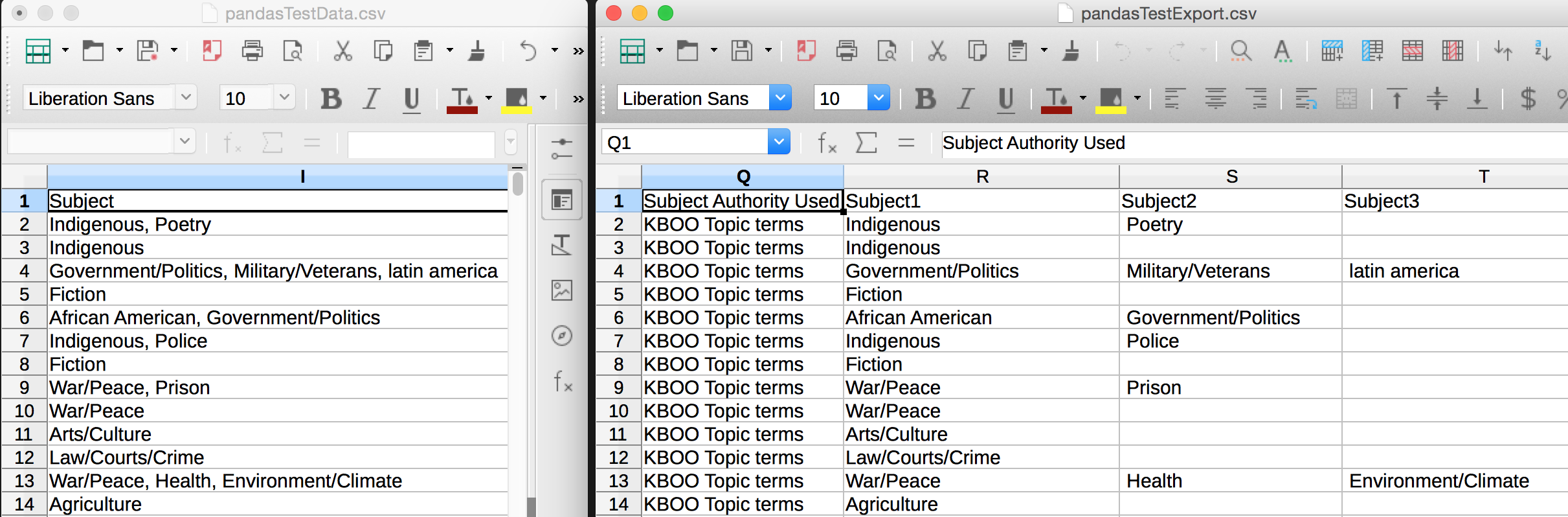
So, I opened the original csv data file, split the subject column data, split the contributor data, and then worked on the rest of the data. If I was to develop this further, I would work on splitting each Contributor Role from the Contributor Name field. Currently this data is entered in a consistent manner, i.e.
Frances Moore Lappe (Guest)
Patricia Welch (KBOO Host)
Jim Hartnet (KBOO Recording Engineer)
Debra Perry (KBOO Host)
Theoretically the data could be split again on the "(" character and the end parentheses could be trimmed.
The Python script and test csv files are on my github: https://github.com/selenachau/kboo-python. Big thanks to @HenryBorchers for looking at my script, suggesting cleaner formatting to make the code easier to reuse down the road, and giving me tips along the way.
Because things seem more difficult in Windows, here are the steps I followed to install Python 2.7 and Pandas on Windows 7 at KBOO.
Download and install python 2.7 at C:\Python27\ from python.org
cmd
run C:\Python27\Scripts\pip.exe install numpy
run C:\Python27\Scripts\pip.exe install python-dateutil
run C:\Python27\Scripts\pip.exe install pytz
run C:\Python27\Scripts\pip.exe install pandas
Here's a blog post that gives an example that you can get hands-on with: https://districtdatalabs.silvrback.com/simple-csv-data- wrangling-with-python